Führend? Waren sie das jemals?
Und das deutet ja dann eher auf ein strukturelles Desinteresse hin, tief in der Gesellschaft verankert.
Das hat ja dann mit Unternehmen erst mal gar nichts zu tun. Die können ja nicht gegen die Stimmung in der Bevölkerung agitieren.
Also erstmal ist nichts „intelligent“ an KI or AI. Das ist eine schlechte Übersetzung aus dem amerikanischen Englisch. Das I muss man wie bei CIA übersetzen, also eher wie Daten sammeln und kombinieren.
Das größte Problem, welches KI verursacht, ist der immense Energieverbrauch. Noch schlimmer als Blockchain. Was hilft KI wenn wir die Ressourcen der Erde noch schneller verbrauchen?
Der Begriff KI bzw. AI hat in der Tat nicht viel mit menschlicher Intelligenz zu tun, „maschine learning“ ist eigentlich besser. Aber die These das es auf „intelligence“ im geheimdienstlichen Sinn zurückgeht, habe ich noch nie gehört. Hast du da Quellen für?
Guter Punkt. Aber den kannst du auch gegen andere Computer-Technologien bringen. Entscheidend für die Bewertung ist eben der Nutzen.
Maschinelles Lernen ist nicht das Gleiche wie KI.
AI bzw KI ist ein weit gefasster Oberbegriff:
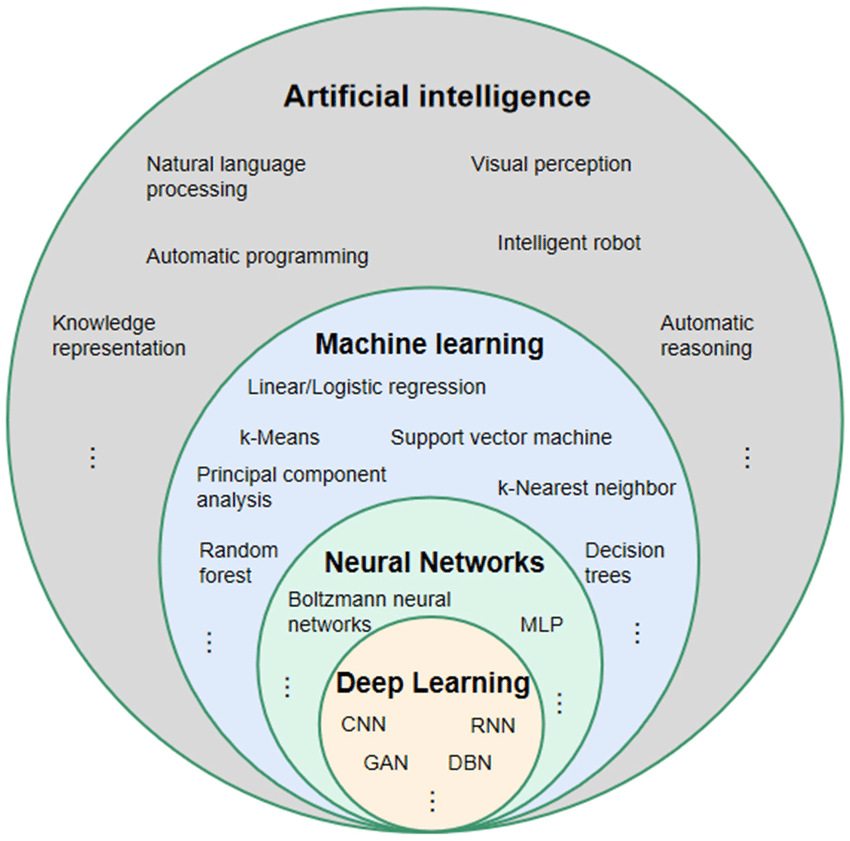
Darüber hinaus haben viele andere Disziplinen (Computer Vision, Robotik, Data Science, etc) große Schnittmengen mit KI im Allgemeinen und zum Teil mit Maschinellem Lernen im Speziellen.
LLMs wie ChatGPT sind nur eine spezifische Ausprägung generativer KI und nicht repräsentativ für den ganzen Bereich.
4 „Gefällt mir“
Tatsächlich ist „Intelligenz“ schon die korrekte Übersetzung des „I“ von „AI“ aus dem amerikanischen Englisch. Der Begriff wurde 1955 von dem amerikanischen Informatiker John McCarthy geprägt und der meinte mit dem „I“ damals tatsächlich Intelligenz im Sinne von menschlicher Intelligenz, also Fähigkeiten wie Lernen, logisches Denken, Problemlösen und Sprachverständnis. Machine Learning ist ein Teilgebiet der KI (die Grafik von sereksim zeigt das ja sehr schön) und kam erst später. Und erst dafür spielte dann natürlich auch das Sammeln von Daten eine große Rolle.
Klar, 70 Jahre lang hat der damals formulierte Anspruch nicht zu dem gepasst, was man tatsächlich technisch hat umsetzen können. Nun beginnt sich das halt zu ändern. Wenn man das McCarthy-„I“ mal auf der y-Koordinate aufträgt, sehen wir eine 70-Jahre lange waagerechte Null-Linie, die nun seit einigen Jahren erstmals einen Knick hat. Wir haben mit den LLMs erstmals Systeme, die „breit“ genug arbeiten, um sie nicht mehr als „Narrow AI“ bezeichnen zu müssen. Tatsächlich liegt die Menge des Text-Materials, dass die Modelle konsumiert haben, um Größenordnungen über dem, was ein Mensch in seiner Lebenszeit jemals lesen kann.
Es ist wichtig zu verstehen, dass die LLMs die gelernten Texte nicht einfach nur nachahmen (wie TilRq das oben formuliert hat) oder geschickt rekombiniert wiedergeben. Sondern durch das Training („Sage das nächste Wort vorher“) werden sie gezwungen, den Sinn hinter den Texten zu erfassen. Also die Ideen und Konzepte dahinter sowie deren (kausale und andere) Beziehungen. Nur so können sie das nächste Wort in einen neuen Text wirklich gut vorhersagen.
Dieses „den Sinn von etwas erfassen“ ist eine übliche Definition des Wortes „verstehen“. Man kann also mit Fug und Recht sagen, dass die Modelle tatsächlich zu einem gewissen Grad verstehen worüber sie reden. Sie ahmen dieses Verständnis nicht einfach nur nach. Auch neurobiologisch gibt es ja Parallelen zwischen den Gehirnen biologischer Lebewesen und neuronaler Netze und Hinweise darauf, dass menschliche Gehirne Information letztlich nicht gänzlich anders prozessieren. Hier stimme ich voll mit diesem Post von Schnackerio weiter oben überein.
Eine bekannte Stimme, die immer wieder darauf hinweist, dass diese Modelle auf ähnliche Weise verstehen, wie auch Menschen verstehen, ist Geoffrey Hinton. Er ist Empfänger des „Turing Awards“ (quasi Nobelpreis der Informatik), der auch als einer der „Godfather of AI“ bezeichnet wird. Interessanterweise hat sich Hinton im Laufe seines Lebens viel auch mit der biologischen Seite (Neurowissenschaften) beschäftigt.
Diese Interview-Ausschnitt bringt Hintons Aussagen relativ plakativ auf den Punkt:

Hier noch ein ausführlicherer Vortrag (Link), in dem er ab min 13:40 auch darauf eingeht, warum Leute es sich zu einfach machen, wenn sie bei den LLMs einfach nur von „Autocomplete“ reden.
2 „Gefällt mir“
Noch ergänzend: Hier ein Interview mit dem KI-Experten Andrew Ng, das in der Financial Times erschienen ist: Link auf Originalversion. Ab ca. Absatz 20 geht es dort auch um die Frage, ob die Modelle die „Welt verstehen können“. Hier die deutsche Version des Artikels: Link auf Google-Translate-Übersetzung.
1 „Gefällt mir“
Ja da habe ich mich etwas unsauber ausgedrückt, denn das wollte ich auch nicht damit sagen. Aber im Kontext dieser Debatte finde ich „Maschinelles Lernen“ besser, da es eher verdeutlicht worum es geht und auch das dabei Computer zum Einsatz kommen.
Bei „Künstlicher Intelligenz“ werden, meiner Meinung nach, zu hohe Erwartungen geweckt, was auch Teil des aktuellen Hypes ist.
@Jens2
Die Diskussion darüber, was „Verstehen“ in diesem Kontext bedeutet, hatten wir ja letztes Ja schon. Die möchte ich aktuell nicht wieder aufmachen. Es hat sich ja auch seit dem nichts Grundlegendes geändert.
Das Deutschland beim ganzen Themenkomplex Computer ↔ Digitalisierung, wie viele europäische Länder auch hinter den USA hinterher „hinken“, hat, meiner Meinung nach, einen wichtigen Grund: Den 2. Weltkrieg.
Die Grundlagen der Computer-Industrie gehen zurück auf die Entwicklung der Transistoren, speziell den Feldeffekttransistor, und deren anschließende Miniaturisierung hin zu integrierten Schaltungen, woraus dann schnell die Mikroprozessoren entstanden. Und das alles fand in den USA statt. Und zwar in den 50ern und 60ern.
Als man in Deutschland z.B. froh war, das man nach dem Wiederaufbau und dem „Wirtschaftswunder“ wieder einigermaßen zu Wohlstand kam, da haben die Amerikaner mit Firmen wie Fairchild und Intel den Grundstein für die spätere Dominanz auf dem Heim- und Bürocomputermarkt gelegt.
Konzerne wie Intel und Microsoft haben, als sie einmal groß waren, ihre Vorreiterrolle nie wieder abgegeben und ihnen stehen gewaltige Investitionssummen zur Verfügung, womit ja Microsoft heutzutage z.B. OpenAI mit Milliarden unter die Arme greift.
Dieser Zug ist also schon seit Jahrzehnten abgefahren.
1 „Gefällt mir“
Bei heise gibt es einen schönen Artikel über eine aktuelle Studie u.a. der TU Darmstadt:
Link zum pdf der Studie:
https://arxiv.org/pdf/2309.01809
Fazit der Studie ist gewissermaßen, dass es durch Hochskalieren von LLM nicht möglich sein wird, emergentes Verhalten oder gar eine AGI zu erreichen:
Die Studie deutete darauf hin, dass die bisher als emergent interpretierten Fähigkeiten eher eine Kombination aus kontextbasiertem Lernen, Modellgedächtnis und sprachlichem Wissen sind.
Eigentlich wenig überraschend, aber gut, dass das jetzt nochmal wissenschaftlich geklärt wurde.
2 „Gefällt mir“
Das wollen die Bitcoin- ähhh AI-Jünger aber nicht hören.
1 „Gefällt mir“
Ich verstehe ehrlich gesagt nicht auf was ihr hinaus wollt.
Was zeichnet hier in dieser Diskussion AI jünger aus?
Wir sollten hier die Fachwelt und die Medienrezeption unterscheiden. Meines Wissens hat kein namhafter _KI-Forscher je ernsthaft davon gesprochen, dass man mit LLMs eine AGI erreicht. Ein Le Cun (zweifellos einer der führenden Forscher auf dem Gebiet) beispielsweise verweist schon seit Jahren unvermindert darauf, dass es ganz neue Modell-Architekturen und Herangehensweisen benötigen wird um eine AGI zu erschaffen - dies letztlich aber erfolgreich sein wird.
Was die Studie untersucht hat ist, ob es emergente Fähigkeiten der LLMs wirklich gibt. Dabei geht es lediglich darum, ob LLMs durch immer weitere Skalierung der Trainingsdaten und Modellstruktur quasi endlos besser werden können. Das hat mit einer AGI genauso wenig zu tun wie ein Isaac Newton mit einem Grundschüler, der vor einem Brockhaus Universallexikon sitzt.
Der Grundschüler kann mit dem Lexikon erfolgreich Lösungen auf Fragen nachschlagen, vielleicht sogar einfache, bekannte Zusammenhänge kombinieren und so neue Dinge schlussfolgern. Und je dicker das Lexikon wird (mehr Trainingsdaten, also Skalierung), umso erfolgreicher wird der Grundschüler. Newton hingegen konnte erkennen, dass es im bestehenden Wissen Inkohärenzen gibt, verwarf daher Vorstellungen, die nicht ins Bild passten und leitete völlig neues Wissen her.
Was manch einer vielleicht durcheinander wirft ist, dass es gar keine AGI braucht um dem Menschen gefährlich zu werden. Die wenigsten Menschen sind nämlich Newtons, DaVincis oder Curies. Das kreative Arbeiten der meisten Menschen unterscheidet sich kaum vom Grundschüler. Nur suchen sie heute bei Google und nicht im Brockhaus.
Und auch unter uns IT-Menschen sind bei weitem nicht alle Masterminds wie Minsky, Nygaard oder ähnliche. Stattdessen wenden (die besseren von uns) erlerntes (bzw. nachgeschlagenes) Wissen wie Design Patterns, Algorithmen oder Heuristiken zum Lösungsdesign, die die Masterminds entwickelt haben, mehr oder minder stumpf an (und das nennen wir dann Best Practice).
Dieses Niveau können LLMs völlig zweifellos erreichen. Es ist nur eine Frage der Zeit und der Skalierung. Menschen die das nicht erkennen, erinnern mich an all die Militäreinheiten, die Anfang des 20. Jhd. lieber noch auf Pferde als auf Panzer setzten, weil Pferde kein Erdöl benötigen, aber auch wendiger, geländegängiger und sowieso viel cooler weil oldschool sind. So kann man fraglos argumentieren, aber es ist schon sehr nah dran an Realitätsverweigerung.
3 „Gefällt mir“
Falls du damit mich gemeint hast: Mir ging es mit dem Beitrag darum, dass wir bei dem Thema maschinelles Lernen von den überzogenen Erwartungen weg kommen und z.B. die Anwendungen von LLM (also Übersetzungen, Internet Recherche usw.) realistisch beurteilen und dann auch sinnvoll einsetzen. Und insbesondere sollten wir LLM nicht für solche sicherheitskritischen Anwendungen in Betracht ziehen:
Ja, wahrscheinlich haben die echten Experten sehr auf ihre Wortwahl geachtet. Aber der Tenor, in den sie letztes Jahr eingestimmt hatten, war unmissverständlich, siehe hier:
Nicht ganz, würde ich sagen.
In ihren eigentlichen Aufgaben, z.B. natural language processing, können LLM durch größere Traningsdaten und Modelle ja durchaus besser werden. Das ist ja auch das, was das ursprüngliche Interesse an den Chatbots befeuert hat.
Aber als „emergent“, im Sinne des Papers oben, werden Fähigkeiten bezeichnet, auf die die KI eben nicht gezielt trainiert wurde, sondern die einfach so aus der Masse der Trainingsdaten entstehen. Und das war eben Wunschdenken oder bewusste Täuschung, je nachdem wie man es sehen möchte.
Ob jetzt LLM oder andere Formen von Algorithmen: wenn ich mir ansehe was auf dem Straßen so gemacht wird, dann kann es nicht viel schlechter laufen als mit dem Menschen als Fahrer.
1 „Gefällt mir“
Aber das ist doch ein mögliches Szenario. Beispielsweise könnte eine KI bewusst oder unbewusst Aufgaben bekommen, die diese nutzt um digitalisierte Waffensysteme zu steuern oder einen einen Militärschlag auf eine Atommacht zu simulieren.
Dafür muss ich der KI nicht direkt beibringen wie man das alles tut, sondern sie nur als Agenten nutzen um Spezial-KIs, die für legitime Zwecke mit spezifischen Fähigkeiten ausgestattet sind, zu steuern.
Dieses Szenario wird sicher nicht morgen eintreffen, aber es ist auch mit Transformern grundsätzlich möglich wenn wir nicht aufpassen.
Nein. Das ist keineswegs Wunschdenken oder Täuschung, sondern schlicht Deep Learning. Was du beschreibst, dass Fähigkeiten aus der Masse der Trainingsdaten einfach so entstehen, liegt in der Natur des Deep Learning. Man muss LLMs eben nicht gezielt auf bestimmte Fähigkeiten hin trainieren, sondern sie entwickeln diese Fähigkeiten selbstständig (oft unerwartet bzw. schwer vorhersagbar), wenn sie mit genug Daten trainiert werden.
Eine ganz gute Einordnung („Explainer“) zu Emergenz bietet dieser Artikel: Emergent Abilities in Large Language Models: An Explainer. Hier die deutsche Google-Translate-Übersetzung.
Im Kapitel „Entstehung von Deep Learning“ heißt es:
Im Deep Learning wird emergentes Verhalten nicht nur toleriert, es ist notwendig. […]
Emergenz ist daher beim Deep Learning die Regel und nicht die Ausnahme. Jede Fähigkeit und interne Eigenschaft, die ein neuronales Netzwerk erlangt, ist emergent; nur die sehr einfache Struktur des neuronalen Netzwerks und sein Trainingsalgorithmus sind entworfen [=durch Menschen programmiert]. Während dies in der Informatik ungewöhnlich sein mag, ist es das nicht für die natürlichen Systeme, von denen neuronale Netzwerke ihren Namen haben."
Philip und Ulf hatten das in LdN366 ja auch sehr schön herausgearbeitet.
Beim Übergang von GPT-3 zu GPT-4 (siehe etwa diesen geposteten Vortrag aus dem letzten Jahr) hat man einige emergente Fähigkeiten sehen können. Etwa im Bezug auf begrenzte „Reasoning“-Fähigkeiten in GPT-4, die vorher so in GPT-3 nicht vorhanden waren. Und diese neuen Fähigkeiten haben rein gar nichts mit In-Context-Learning zu tun - also der Fähigkeit von LLMs innerhalb ihres Kontextes (=ihrer aktuellen Konversation) zu lernen. Sondern diese Fähigkeiten haben sich während des langwierigen Trainigsprozesses (Pretraining) emergent entwickelt, sind also in den Gewichten des Modells verankert (nicht im flüchtigen Kontext).
Nein und Ja. Aus dem Vorangegangenen sollte klar geworden sein, dass man durch das Skalieren von LLMs emergentes Verhalten nicht nur erreichen, sondern erwarten kann. Wie turmfalke schon sagte, geht aber niemand davon aus, dass man durch einfaches Skalieren der aktuellen Modelle alleine AGI erreichen kann. Es sind weitere Durchbrüche nötig (etwa in Bezug darauf, was manchmal als „System 2 Thinking“ bezeichnet wird, siehe die Ausführungen zu Kahneman weiter oben).
4 „Gefällt mir“
Wieso „Was du beschreibst“? Das stammt nicht von mir, das steht in dem Paper, dass ich zitiert habe.
Ich bleibe dabei und sehe es wie Johanna Seibt bei Heise:
Systeme wie ChatGPT sind stochastische Papageien.
Das größte Problem wird die Fehlerkorrektur, wenn falsche Informationen gelernt oder absichtlich (z.B. durch Akteure wie MAGA oder Putin) injiziert werden.
(Missing Link: Werden KI-Systeme wie GPT "stochastische Papageien" bleiben? | heise online)
2 „Gefällt mir“
Na ja, sie ist Philosophin und keine KI-Expertin. Interessant aber, dass sie auch die psychologischen Gründe nennt, warum Menschen, die durch KI verunsichert sind, dazu neigen, Systeme wie ChatGPT als „nur Mathematik“ abzutun:
Das scheint mir eine gängige Strategie zu sein, um der Verunsicherung durch KI zu begegnen: Wann immer sie den Menschen bei einer Aufgabe übertrifft, sei es beim Schach, beim Go oder beim Erkennen von Verkehrszeichen, heißt es oft, das sei ja „nur Mathematik“, keine wirkliche Intelligenz. Ich spüre dahinter den dringenden Wunsch, dass das menschliche Denken ein einzigartiges Mysterium bleiben möge.
Zu Beginn der industriellen Revolution war es für Menschen weniger ein Problem zu akzeptieren, dass Maschinen stärker sein können als Menschen. Schließlich gab es ja bereits Tiere, die stärker waren als wir. Bei der Intelligenz ist das anders. Hier sehen wir uns zu Recht an der Spitze der Evolution. Umso schwerer fällt es vielen, KI-Systemen auch nur ein wenig Intelligenz zuzugestehen - denn das würde ja bedeuten, dass KI - wenn sie weiterentwickelt wird - irgendwann intelligenter sein könnte als wir.
2 „Gefällt mir“
Der Begriff „stochastischer Papagei“ geht auf ein Papier aus dem Jahre 2021 zurück (Link) und wird häufig von KI-Skeptikern verwendet, wenn sie zum Ausdruck bringen wollen, dass diese Systeme nicht wirklich verstehen, sondern Dinge einfach nur nachplappern.
Wie oft in der Wissenschaft gibt es verschiedene Fraktionen und Denkschulen. Das Papagei-Papier wurde von Computerlinguisten verfasst und man muss wissen, dass Computerlinguisten in der Sprachverarbeitung traditionell auf symbolische KI-Ansätze gesetzt haben. Also vereinfacht gesagt auf die regelbasierte Zerlegung von Sätzen in ihre Bestandteile wie Subjekt, Prädikat, Objekt usw… Das Aufkommen von Deep Learning hat (insbesondere zu Beginn) bei vielen Computerlinguisten zu Skepsis und Ablehnung geführt, weil diesen Systemen die expliziten Regeln fehlen und ihre Funktionsweise schwer nachvollziehbar ist. Eine schillernde Leitfigur auf diesem Gebiet ist der ehemalige Linguistik-Professor (und mittlerweile 96 Jahre alte) Noam Chomsky (hier in einem Video zu ChatGPT).
Hinton geht in diesem schon weiter oben zitierten Talk (ab min 5:43) auf die Linguisten und auf Chomsky ein. Ab min 13:20 auch auf die (vor allem aus der Chomsky-Ecke kommenden) Einwände, die LLMs seinen gar nicht wirklich intelligent, sondern nur eine Form von glorifiziertem Autocomplete (eine andere Bezeichnung für „stochastische Papageien“).
Problematisch finde ich, wenn einige Publikationen - wie etwa netzpolitik.org - sehr einseitig nur die Chomsky-Linie vertreten anstatt das Thema KI faktenbasiert und vor allem faktenoffen zu betrachten. Aber ich glaube, diese skeptische Sicht auf KI ist in der Tendenz auch eine Eigenschaft der gesamten deutschen Blase.
2 „Gefällt mir“