Das sehe ich auch so. „⊃“ heißt übrigens Teilmenge. Nur als Hinweis, damit die Unterhaltung hier nicht zu nerdig wird. 
Nicht wirklich.
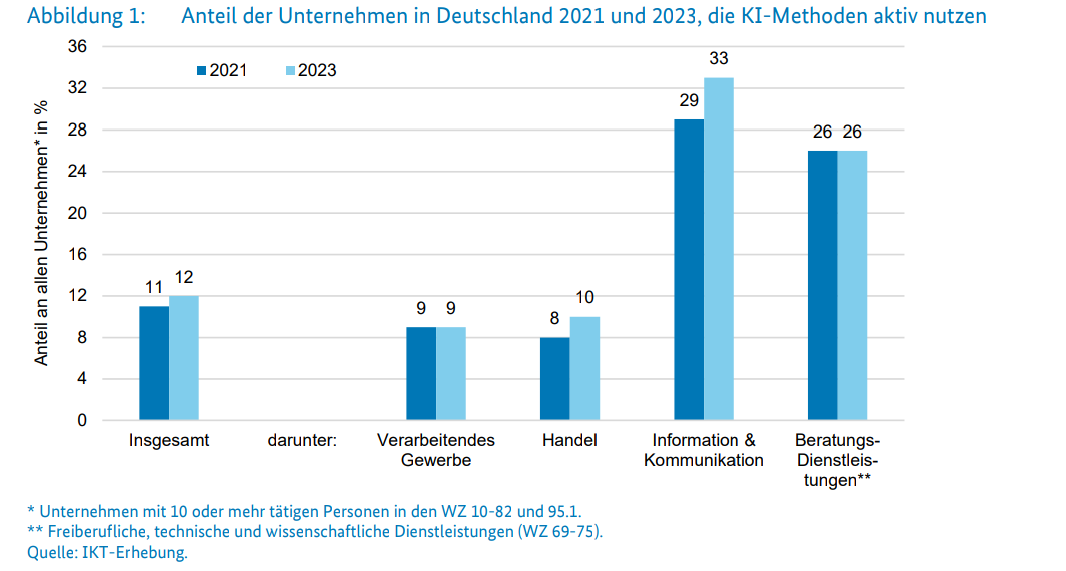
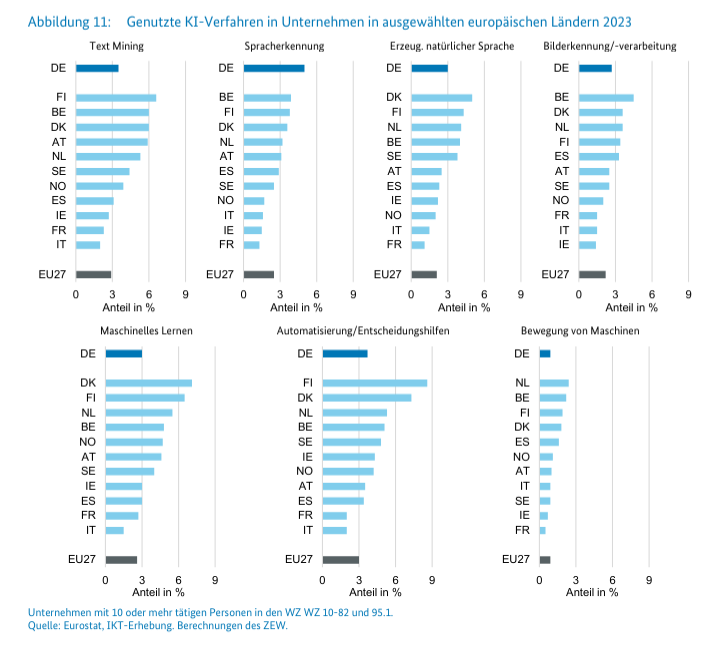
Aber der aktuelle Hype um LLM führt leider zu völlig überzogenen Erwartungen. KI lässt sich prima für Sprachverarbeitung und Bilderkennung benutzen, aber das war auch schon vor dem ChatGPT-Hype so und wird auch danach wieder so sein.
Aber im aktuellen Hype werden KI-Software einfach völlig unmögliche Fähigkeiten zugeschrieben. Es wird übertrieben viel Geld auf das Thema geworfen sowohl von Unternehmensseite als auch von öffentlichen Stellen.
All das hat aber wenig bis gar keinen echten Grund sondern liegt nur an der übertriebenen öffentlichen Aufmerksamkeit, die ChatGPT generiert hat, weil es plötzlich „sprechen kann“.
Das triggert bei Entscheidern in Firmen und großen Behörden die Angst, dass man einen erkennbaren Fehler machen würde, wenn man sich nicht mit dieser Technik beschäftigt bzw. dort investiert. Und aus dieser Angst werden unüberlegte Entscheidungen getroffen. Und leider gibt es auch immer sofort Firmen, die solche unüberlegten Entscheidungen ausnutzen und Geld abgreifen, dass besser in sinnvolleren Projekten investiert wäre, auch wenn das weniger „sexy“ ist.
War das ein „Freud-scher Versprecher“? 
Aber Spaß beiseite. Ich bin Techniker und als Techniker bin ich natürlich davon überzeugt, dass man mit Technologie vieles besser machen kann (wenn auch nicht alles). Aber dafür muss man die Technologie objektiv bewerten. Man muss Kosten und Nutzen (und Anforderungen) genau gegeneinander abwiegen.
Mal ein Extrembeispiel: Wer sich eine Solaranlage aufs Dach baut und dann meint, er könne seinen Stromanschluss kündigen, der wird sehr schnell eine böse Überraschung überlegen. Das macht natürlich keiner, weil der Zusammenhang Solarenergie ↔ Sonnenlicht auch für Laien sehr leicht zu überblicken ist.
Bei der LLM-Technologie (bzw. Deep-Learning allgemein) ist das viel schwerer, weil die Technik viel komplizierter ist. Und schon die Tatsache, dass diese Technik nur da funktioniert, wo extrem große Mengen an Trainingsdaten verfügbar sind (wie z.B. Texte im Internet), scheint vielen nicht klar zu sein.
Daher ist es mMn einfach wichtig, auf solche und ähnliche Limitierungen immer wieder hinzuweisen.