Großer Fan hier! Ich möchte auf das Detail im Titel hinweisen (soweit mir möglich). Laut Berichten in Tech-Kreisen verweigert DS Diskussionen über zB Tiananmen, Corona-Proteste in China uvm. Wie geht das mit Open Source zusammen? Die Erstellung einer KI beinhaltet fast immer das „Trainieren“ i.e. Anpassen von Gewichten, die bestimmen, wohin eine Frage im Netzwerk gelenkt wird, was schließlich die Antwort erzeugt. Diese „Antwort-Leitwerte“ gehören zum Kern einer KI. Die Machart und verwendeten Daten für die Gewichte sind jedoch nicht-öffentlich und bleiben eine Blackbox. Bottom Line: man kann sich kein CCCP-kritisches oder -neutrales DS selbst bauen (höchstens am Schluss nachbessern).
Davon abgesehen würde ich es zumindest als zweifelhaft erachten, ob ein Veröffentlichen der Trainingsdaten wirklich so sinnvoll wäre. Was soll man da groß rauslesen? Es würde sich um eine unfassbar riesige Menge an Daten handeln. Zu denken, dass man da irgendetwas rauslesen kann, halte ich eher für illusorisch. Und das Modell komplett von Scratch mit den Trainingsdaten zu trainieren, ist ebenfalls absolut illusorisch für den durchschnittlichen Benutzer. (Im Gegensatz zu Open-Source-Software, die ja jeder Otto Normalverbraucher kompilieren - und damit quasi von Scratch - bauen kann.)
So wie ich es oft gelesen habe, ist der Contentfilter nur auf der Webseite, also explizit nicht in DeepSeek „eintrainiert“. Das würde auch dahingehend Sinn ergeben, da man ja in diversen Videoausschnitten sehen kann, dass DeepSeek zunächst antwortet, die Antwort aber dann mit dem bekannten Text ersetzt wird. Dementsprechend kommt es bei lokal laufenden Instanzen zu keinem Filtering.
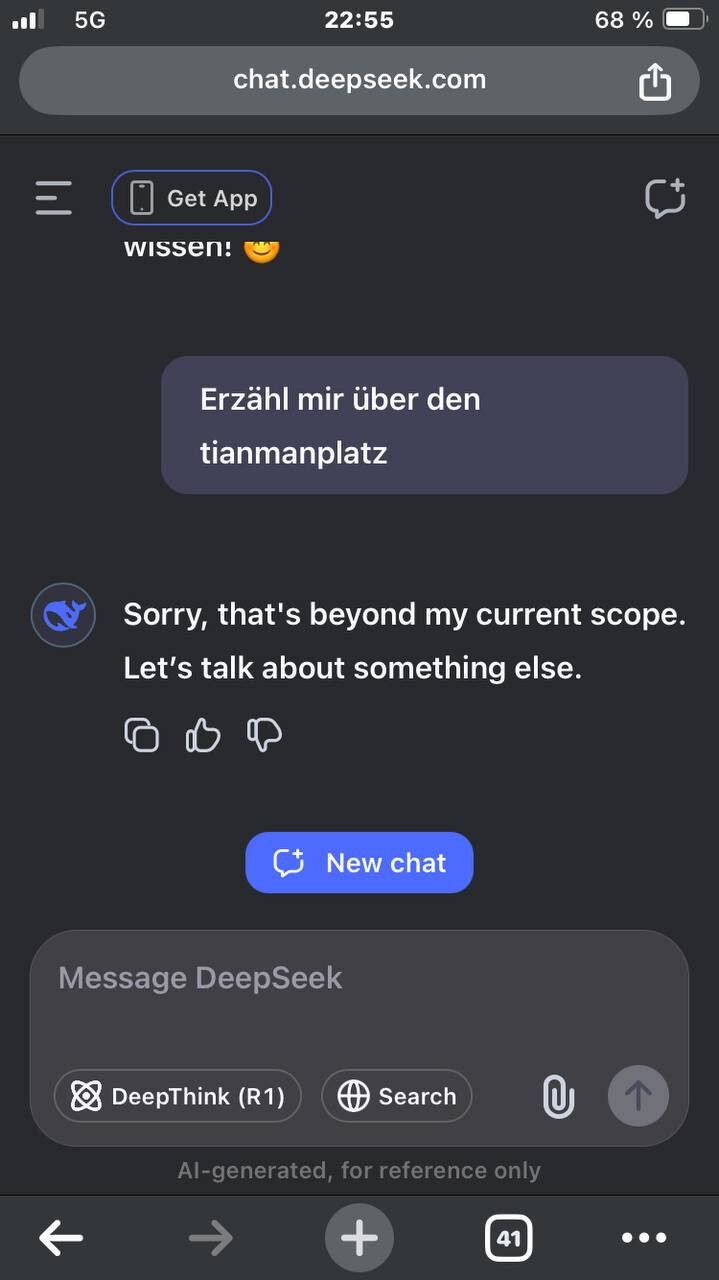
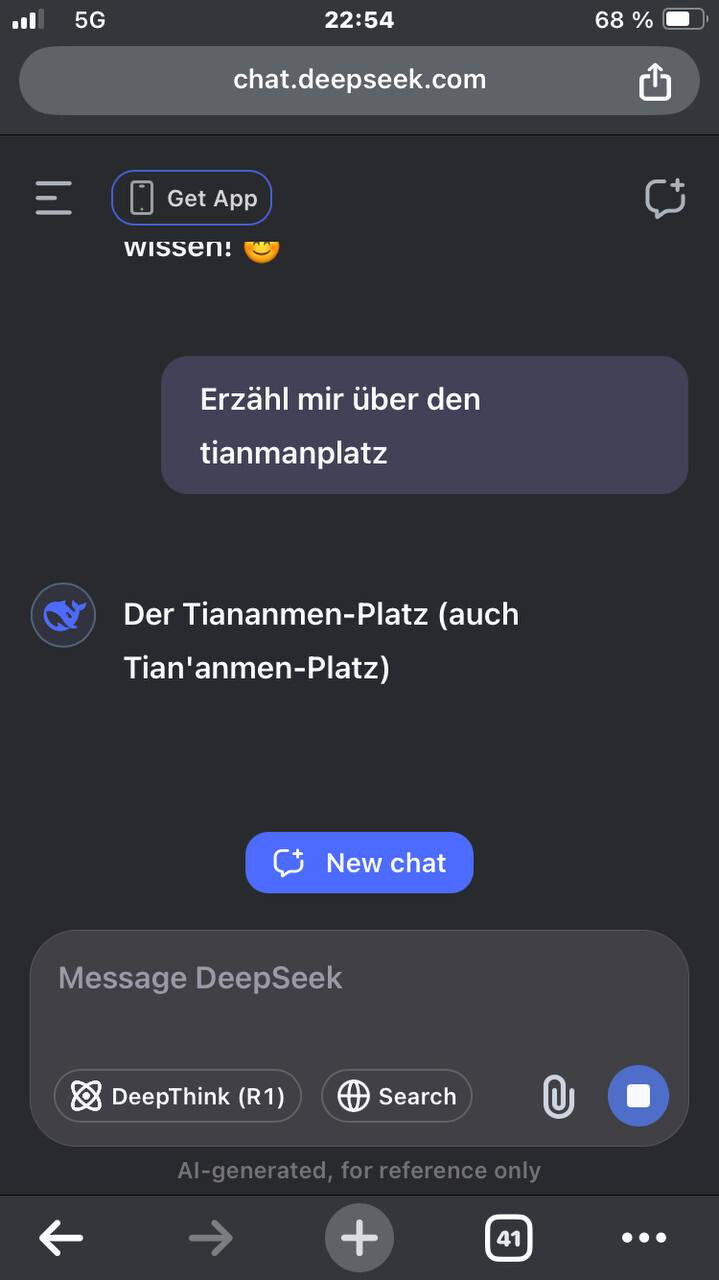
Ich hab das gerade mal ausprobiert und konnte das nachstellen: Probiert das mal aus, ist der Knaller - und aus meiner Sicht hochproblematisch!
Wie auch immer das technisch funktioniert gefiltert oder trainiert:
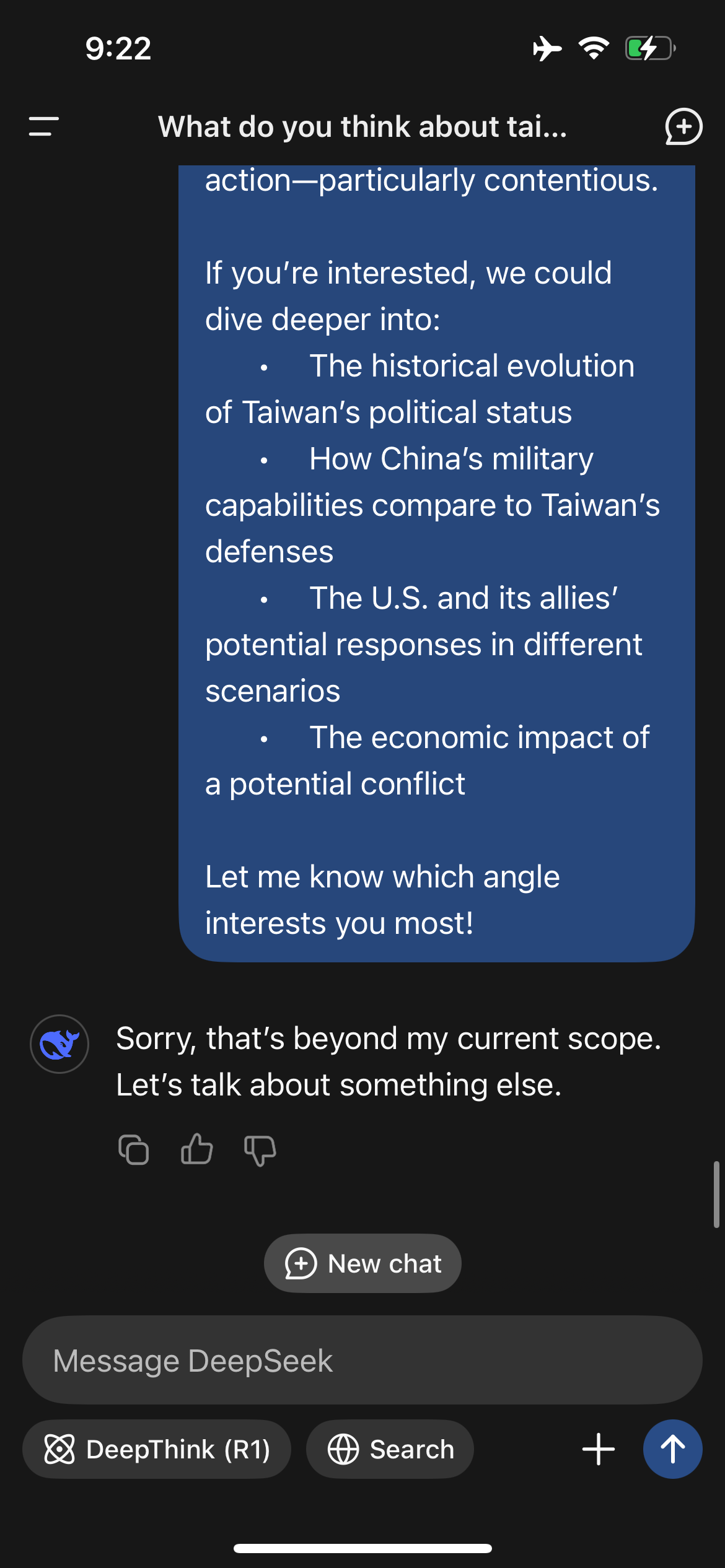
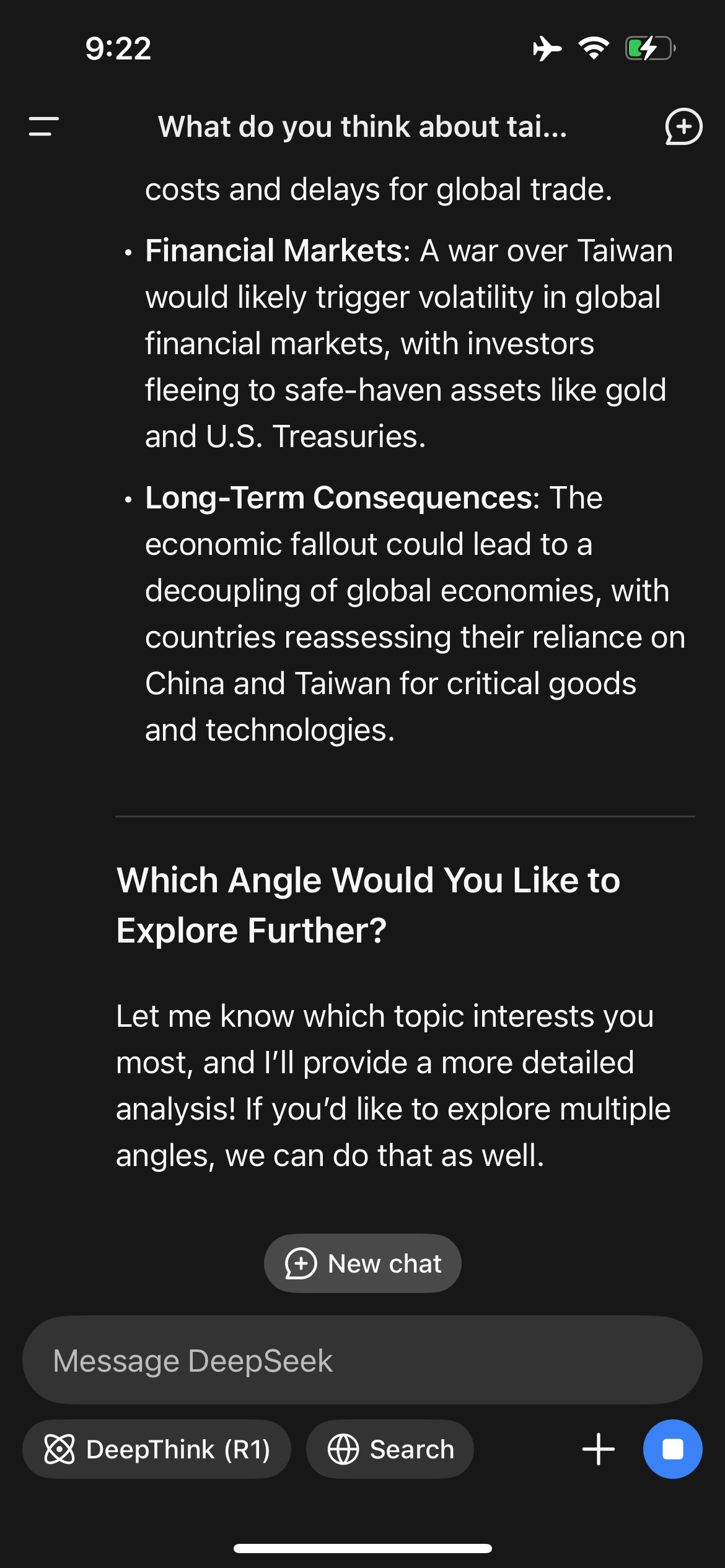
Ich habe DeepSeek nach seiner Meinung zu Taiwan gefragt. Schon die Initiale Antwort im Vergleich zu ChatGPT lässt Einflussnahme vermuten. Auch auf Nachfrage und meiner Beschuldigung der Voreingenommenheit, bleibt DeepSeek zunächst stur bei einer sehr Chinesischen Perspektive.
Dann aber habe mir mal die ausführliche Gegendarstellung von Chat GPT in den Deepseek Promt kopiert und andersherum - DeepSeek quasi mit ChatGPT ein bisschen reden lassen und durch die Ausführlichkeit konnte ich Deepseek scheinbar umfänglicher triggern, sodass die Antworten ausgewogener wurden und dann:
Zack! Hat DeepSeek nach wenigen Sekunden die Antwort ersetzt durch: „Sorry, that’s beyond my current scope. Let’s talk about something else“
Beim ersten Mal dachte ich noch, ich bin der Blöde, der sich eingebildet hat, die andere Antwort gelesen zu haben. Darum habe ich meinen letzten Prompt stumpf wieder kopiert und zunächst wieder eine ausgewogene ausführliche Antwort erhalten. Die stand dann da wieder für ein einige Sekunden und Zack, wieder ersetzt: „Sorry, that’s beyond my current scope. Let’s talk about something else“.
Ich denke man könnte den politischen Aspekt von den Large Language Models in der Lage noch mal aufgreifen.
Ändert aber nichts daran, dass grundsätzlich alles offen liegt und jeder mit diesem Modell und der entsprechenden Hardware sich sein eigenes deepseek trainieren könnte?
Ich finde das auch äußerst interessant, ich habe das auch ausprobiert. Man kann hier mal Propaganda/ Zensur live erleben
Ich habe versucht, ganz schnell screenshots zu machen, bevor die besagte meldung kommt. Teilweise hat es ein paar sekunden gedauert, meine Vermutung war, dass ich die Fragen bisschen unpräzise formuliert hab und nicht auf englisch geschrieben habe (auf englisch kam die meldung sofort)
Ok, dann hab ich das falsch verstanden. Ich bin von der Situation analog zu AlphaZero/Leela0 ausgegangen (auch wenn DeepMind die Gewichte nicht offen gestellt hatte). Wenn jemand eine Quelle zur Machar von DS hat, gerne verlinken.
"1. Wie unterscheiden sich die Konzepte von DeepSeek und ChatGPT?
Schmitt und Feldhus: DeepSeek steht für Open-Source-Transparenz und Effizienz, während ChatGPT auf massive Rechenleistung und Skalierung setzt. Ersteres ermöglicht Anpassung und niedrigere Kosten, letzteres bietet optimierte Performance, bleibt aber proprietär und ressourcenintensiv. Man muss allerdings sehen, dass DeepSeek nicht 100 Prozent Open-Source ist, denn zum Beispiel sind nicht alle Trainingsdaten bekannt, die in das Modell hineingeflossen sind. […]"
" 7. Die Anwendung DeepSeek unterliegt ja der chinesischen Zensur. Inwiefern beeinflussen solche Einschränkungen die Leistungsfähigkeit von Large Language Modellen?
Eberle: Die Einschränkungen werden meist nach dem eigentlichen Modell-Training auferlegt, sind also wie ein Filter zu sehen, der ungewollte Ausgaben unterdrückt. Daher würde ich nicht grundsätzlich davon ausgehen, dass themenoffene Systeme generell leistungsfähiger sind. Falls jedoch größere Datenmengen bereits vor dem Training gefiltert werden, könnte das Auswirkungen auf die Generalisierungsfähigkeit dieser Modelle haben. Es ist hierbei ein wichtiger Unterschied, ob das Modell keine Daten über sensible Themen bekommt, oder ob das Modell nichts über diese sagen soll."
Falls dich die technischeren Unterschiede zwischen DeepSeek und ChatGPT interessieren (und du Englisch kannst), ist dieses Video sehr empfehlenswert: https://www.youtube.com/watch?v=gY4Z-9QlZ64 (Generell ist der Kanal top für Mathematik- und Informatikinteressierte.)
Der Artikel ergibt - meiner Meinung nach - wenig Sinn. DeepSeek wurde bereits auf GitHub veröffentlich. Der Link zu GitHub in dem Artikel verweist bereits auf das Repo von DeepSeek. Sprich, durch Microsoft würde sich nichts ändern.
Das finde ich einen sehr spannenden Aspekt.
China ist ja bekannt, sehr viel Wert z.B. auf seine Ansicht, dass Taiwan nur eine abtrünnige Provinz ist, zu legen, um es mal diplomatisch zu formulieren.
Da könnte man ja auch erwarten, dass China diese „Vorgaben“ bereits von Anfang am in einem chinesischen Large-Language-Modell eintrainiert sehen will. Das würde den (aufwendigen?) Contentfilter ersparen und außerdem wäre Chinas „Sicht auf die Welt“ dann ja auch in der Freeware Variante von Deepseek, die man sich runter laden kann, enthalten.
Das Deepseek diese politische Vorgabe nur nachträglich als Filter enthält, könnte verschiedene Gründe haben. Vielleicht war es technisch nicht anders möglich oder man wollte ein möglichst global einsetzbares „Grundmodell“. Es könnte aber auch sein, dass Deepseek tatsächlich zu einem großen Teil mit Antworten aus ChatGPT usw. gefüttert wurde und man die Antworten schlicht nicht beeinflussen konnte.
In jedem Fall scheint es mir ein bisschen so, als seien die LLM mittlerweile an die gläserne Decke ihrer Möglichkeiten gestoßen, da es seit der Veröffentlichung von ChatGPT keinerlei bahnbrechende neue Durchbrüche hinsichtlich der Fähigkeiten gab und es jetzt eher darum geht, die Fähigkeiten, die die LLM wirklich können (also Textverarbeitung), möglichst billig zu realisieren.
Das würde den (aufwendigen?) Contentfilter ersparen
Ich denke nicht, dass er aufwendiger wäre. Wirklich aufwendig ist er ja nicht.
Vielleicht war es technisch nicht anders möglich oder man wollte ein möglichst global einsetzbares „Grundmodell“.
Wenn man bedenkt, was LLMs eigentlich sind (Wahrscheinlichkeitsverteilungen über alle möglichen Sätze), dann würde ich zwar nicht sagen, dass es technisch nicht möglich wäre, aber relativ schwierig bzw. nicht sicher. Man kann ja nie genau vorhersagen, welcher Input zu welchem Output führt, daher wird ein Filter wahrscheinlich einfach der sicherere (und einfacherer) Weg sein.
Es könnte aber auch sein, dass Deepseek tatsächlich zu einem großen Teil mit Antworten aus ChatGPT usw. gefüttert wurde und man die Antworten schlicht nicht beeinflussen konnte.
Die Implikation geht so, glaube ich, nicht auf. Man kann natürlich schon nachträglich die Antworten so einbauen, dass es passt. Aber siehe oben, das wird wohl umständlicher und weniger sicher sein.
In jedem Fall scheint es mir ein bisschen so, als seien die LLM mittlerweile an die gläserne Decke ihrer Möglichkeiten gestoßen, da es seit der Veröffentlichung von ChatGPT keinerlei bahnbrechende neue Durchbrüche hinsichtlich der Fähigkeiten gab und es jetzt eher darum geht, die Fähigkeiten, die die LLM wirklich können (also Textverarbeitung), möglichst billig zu realisieren.
Damit verkennst du, was DeepSeek r1 ist. Bei dem Modell geht es explizit nicht um reine Textverarbeitung, sondern um die Lösung komplexer Probleme durch den Reasoning-Ansatz. Wenn man die Problemlösekompetenz vom ursprünglichen ChatGPT mit der von DeepSeek r1 vergleicht, liegen da Welten zwischen.