Du hast ja bereits sehr gute Antworten bekommen. An denen möchte ich auch nichts ändern. Ich will aber vielleicht noch mal eine etwas andere Perspektive geben, die ein bisschen mehr zur grundlegenden Funktionsweise von LLMs aufzeigt und dir somit eine bessere Intuition gibt.
Disclaimer: Wie @HokusPokus1 bereits zurecht angemerkt hat, sind ChatGPT und Co aktuell weit mehr als nur einfache LLMs, sondern können Internetsuchen oder andere Tools nutzen. Daher würde ich behaupten, dass das falsche Wiedergeben von Quellen - sofern ChatGPT eine richtige Recherche ausführt - heutzutage weniger ein Problem ist als zu Beginn. Wenn ein LLM eine Quelle hat, dann kann es diese in der Regel sehr gut zusammenfassen.
Aber gerade am Anfang hat man ja doch oft gesehen, dass ChatGPT irgendwelche Quellen erfindet. Manchmal gab es zwar sogar die Artikel, aber der Inhalt stimmte überhaupt nicht zu der Aussage von ChatGPT. Woran liegt das also?
Ich möchte dir das mit einem dir vielleicht bekannten, mathematischen Konzept erklären: lineare Regression.
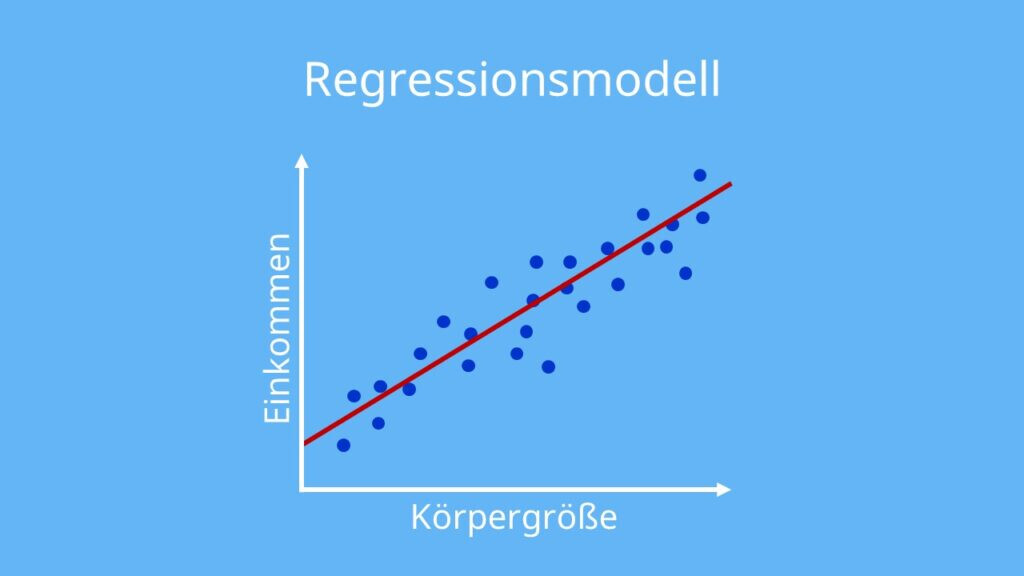
(Ich hoffe, man sieht das Bild so, wie ich es beabsichtige.)
Bei der linearen Regression geht es darum, dass man einige Datenpunkte - Messwerte aus der echten Welt - hat und versucht, den generellen Trend zu erfassen. Dies geschieht häufig dadurch, dass man versucht, eine Gerade so durch die Punkte zu legen, dass die Gerade zwar nicht durch alle Punkte genau verläuft - das geht oftmals gar nicht, wenn die Punkte tatsächlich nicht auf einer gemeinsamen Geraden liegen -, sondern die Gerade soll den “Trend“ entdecken. Man geht davon aus, dass die Messwerte einige Messfehler haben und daher nicht genau auf der gefundenen Gerade liegen. Gleichzeitig möchte man keine komplexere Funktion, die zwar durch alle Datenpunkte exakt verlaufen würde, aber dafür nicht den “Trend“ genau abbildet. Vielmehr würde eine solche Funktion die Messfehler exakt abbilden und so vermutlich eine schlechtere Beschreibung der Realität sein als die einfache Gerade, die zwar nicht alle Punkte trifft, dafür aber den Trend/die Realität besser beschreibt.
So viel zur Theorie. Die Frage ist, was bringt so eine Regression? Sie hat im Endeffekt zwei Vorteile. Zum einen können wir mithilfe der Geraden Werte berechnen, für die wir keine Messwerte haben. Wenn wir das Beispiel aus dem Bild nehmen, dann haben wir ja ganz viele echte Paare von Körpergröße zu Einkommen. Wenn wir einen Messwert zu Körpergröße 1,8 m haben, können wir den entsprechenden Einkommenswert für diesen Messwert ablesen. Was aber, wenn wir zur Körpergröße 1,65 m keinen Messwert haben? Da wir ja jetzt eine Gerade haben, die den Trend Körpergröße zu Einkommen abbildet, können wir einfach anhand der Gerade ablesen, welches Einkommen zu dieser vorher nicht gemessenen Körpergröße gehört.
Zweitens dient eine Regression der Kompression. Eine solche Gerade ist eine lineare Funktion y = m*x+b, die wir abspeichern können, indem wir nur die Werte für die beiden Parameter m und b abspeichern. Die eigentlichen Messwerte (was in der Realität eine riesige Datenmenge sein könnte) können wir “löschen“, da wir mithilfe der Regressionsgerade quasi eine kompakte Repräsentation des zugrundeliegenden Trends haben.
Was hat das alles mit LLMs zu tun? Nun, LLMs sind (stark vereinfacht gesagt) nichts anderes als Regressionen. Wie bereits gesagt bestehen LLMs aus neuronalen Netzen. Das ist ein fancy Wort. Aber eigentlich ist ein neuronales Netzwerk nichts anderes als eine mathematische Funktion. Diese Funktion ist zwar deutlich komplizierter als das Beispiel der lineare Funktion von oben, aber im Prinzip funktioniert es genauso. Die Messwerte aus dem oberen Beispiel sind im Falle von LLMs Sätze, Wörter, Texte etc, und beim Training von LLMs wird eine Regression auf diese Daten ausgeführt. Beim Training versucht man also, die Funktion des neuronalen Netzwerkes so anzupassen, dass diese den Trainingsdaten, also Wörter, Texte etc. möglichst gut “approximiert“ bzw. den Trend erkennt. (Um genau zu sein, trainiert man das neuronale Netz so, dass es - gegeben einem Text - die Wahrscheinlichkeiten für jedes mögliche, nachfolgende Wort berechnet. Und das Ziel beim Training ist, dass für das “richtigen“ nächstem Wort die höchste Wahrscheinlichkeit berechnet wird.)